Tech
为什么机器学习这么难
最近几年,在使机器学习更易接近方面已经取得了巨大进步。在线课程已经涌现出来,精写的教科书把最尖端的研究收纳为更易消化的格式,无数的框架出现来抽象化那些与建构机器学习系统相关的低级杂乱问题。在某些情况下,这些进步使得可以直接将已有的模型放入你的应用,只需要对算法的工作方式有基础理解并用几行代码即可。
然而,机器学习仍然是一个相对‘困难’的问题。毫无疑问,通过研究推进机器学习的科学是困难的。这需要创新性,实验性和坚韧性。机器学习在实现已有的算法和模型使其适应你新的应用进行良好工作时,也是个困难的问题。在工作市场上,机器学习专业的工程师的薪水仍高过标准软件工程师。
这个困难往往不在数学上 - 因为上述的框架,机器学习的实现并不需要深奥的数学。这个困难部分包括对使用何种工具来解决问题有一个直觉感。这需要理解可用的算法和模型,每一个的权衡和约束。单是这种技能就需要对这些模型(课程,教科书,论文)有透彻了解,甚至更多的需要尝试自己实现并测试这些模型。然而,在计算机科学的所有领域都有这种知识建设,并不是机器学习独有的。普通的软件工程需要对各边际框架,工具和技巧的权衡有透彻了解,并做出审慎的设计决定。
困难在于机器学习的基本上是一个极度困难的调试问题。机器学习的调试在两种情况下进行:1)你的算法无法运作或2)你的算法运作不够好。机器学习特殊之处在于,当事情并不像预想那样进行时,找出问题出在哪里会‘指数级’的困难。加剧这调试困难的是,在实现修复或者升级和看到结果之间往往有着调试周期的延迟。很少有算法一次就能运作成功,所以这最后就导致在建构算法时,大部分时间都是花费在这里。指数级困难性的调试
在标准软件工程中,当你为一个问题找到一个解决方案,事情并不如你预期的时候,你的问题往往在两个方向上出错:算法问题或实现问题。比如,以一个简单的递归算法为例:
def recursion(input):
if input is endCase:
return transform(input)
else:
return recursion(transform(input))
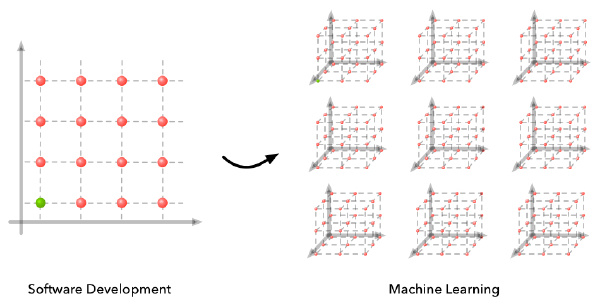
我们可以列举一些此代码没有如预期的那样运作的失败案例。在这个例子中,网格可能会展示像这样:
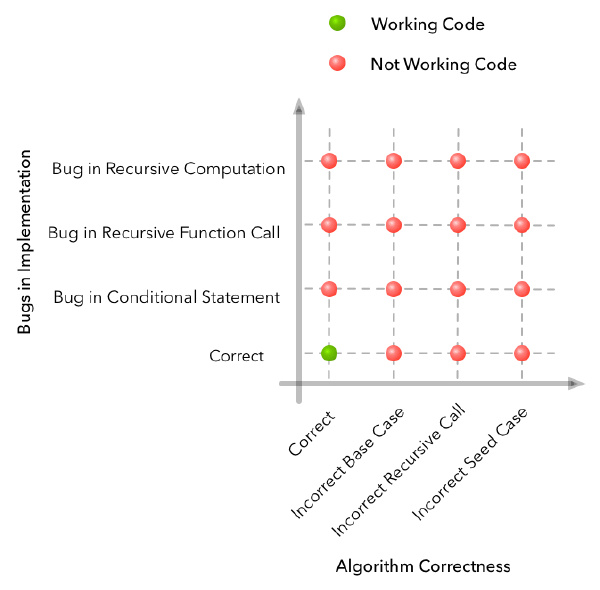
在水平轴上,我们有一些可能我们在算法设计中犯错的例子。在竖直轴上,我们有一些可能我们在算法实现中出错的例子。我们可能会以其中一个维度有一个组合的问题(即多个实现过程中的bug),但是只有当算法和实现都正确的时候,我们才能有一个完美的解决方案。
调试过程就变成了将你对这个bug的了解(编译器误差信息,程序输出等等)和你预感问题可能出在哪里的直觉结合的过程。这些信号和经验帮助你把可能的bug的搜索范围修剪成可以管理的大小。
在机器学习流程的情况下,有两个额外的维度可以发现常见的bug:实际模型和数据。为了解释这些维度,最简单的例子就是使用随机梯度下降训练逻辑回归。这里的算法正确性涵盖了梯度下降更新方程的正确性。实现正确性包扬了特征和参数更新的正确计算。数据中的bug通常涉及到标签的噪声,预处理中的错误,没有正确的主导信号,甚至是数据不足。模型中的bug可能涉及到模型的实际限制。比如,当你的真正决策边界是非线性的时候,你在使用线性分类器。
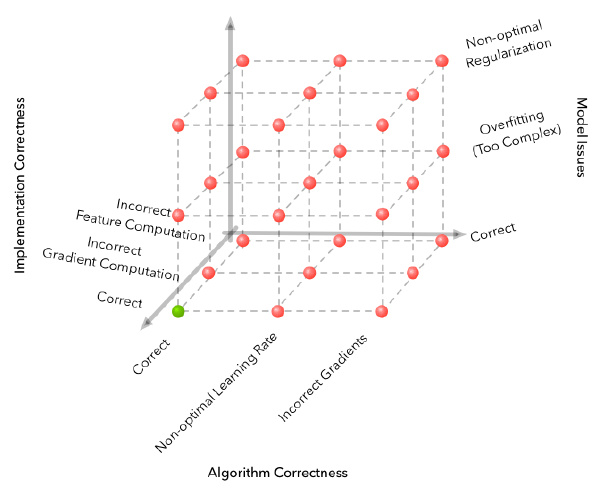
我们的调试过程从一个2D的网格变成一个4D的立方体(用上图明确地画出3个维度)。第四个数据维度可以被想象为这些立方体的序列(注意只有一个立方体是正确的)。
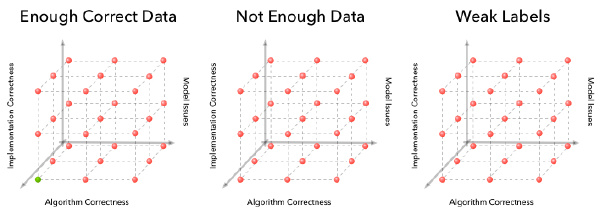
为什么这会是‘指数级’更困难是因为一个维度上有n种可能出错的方法,那么2D上可以有n x n种, 4D上就有 n x n x n x n种。基于可得信号建构出错误可能在哪里的直觉变得更加关键。幸运的是,对于机器学习算法,你还有更多的信号来找出消失在哪里。 例如,特别有用的信号可能是你在训练和测试集上损失函数的图表,你的算法在你的开发数据集上实际输出,以及你的算法中间计算的总结统计。延迟调试周期
复合机器学习调试问题的第二个因素是长的调试周期。实现一个可能的修复和得到改变是否成功的信号之间,往往需要数小时乃至几天。我们从网页开发中知道,使得自动刷新可能的开发模式可以大幅度提升来开发者效率。这是因为你可以将中断发展的流程降到最低。这在机器学习中经常是不可能的 - 在你的数据集上训练一个算法可能需要几小时或几天的时间。在深度学习中的模型特别容易受到这种调试周期延迟的影响。长的调试周期使得‘并行’实验范例成必要。机器学习的开发者会运行多重实验,因为瓶颈往往在算法的训练上。通过并行开发,你希望运用指令流水线(对于开发者而不是处理器)。这种被迫以这种方式工作的重大弊端是你无法利用你聚积的知识顺序调试或实验。
机器学习常常归结为,当事情可能会以许多方向出错 (或者可以更好) 的时候,为何事情偏偏出错在哪里(或者哪里可以做得更好)这样一个本能。当你继续建构机器学习项目的时候,你开始对哪里可能存在问题的行为信号有更深的理解。在我自己的工作中,有很多这样的例子。例如,最早在我训练神经网络时遇到的问题之一就是,在我的训练损失函数中存在周期性。 损失函数在处理数据时会衰减,但经常会跳回到一个更高的值。经过很多次试验和错误后,我最后明白这通常是训练集没有被正确随机化 (这看上去是数据问题但实则是实现问题) 的结果,这在你用每次处理小块数据的随机梯度算法时会成为问题。
总之,快速和有效的调试是实现现代机器学习流程最需要的技能。
本文译自 Zayds Blog,由 BALI 编辑发布。